Threadpull: Building an influence mapper with Claude and LangGraph
February 25, 2026
I built Threadpull: a political influence mapper. The user provides a company name or politician, and the system maps influence networks across lobbying disclosures, campaign donations, federal contracts, and congressional voting records. I wanted to see who’s connected to whom in a way you can’t get from headlines alone.
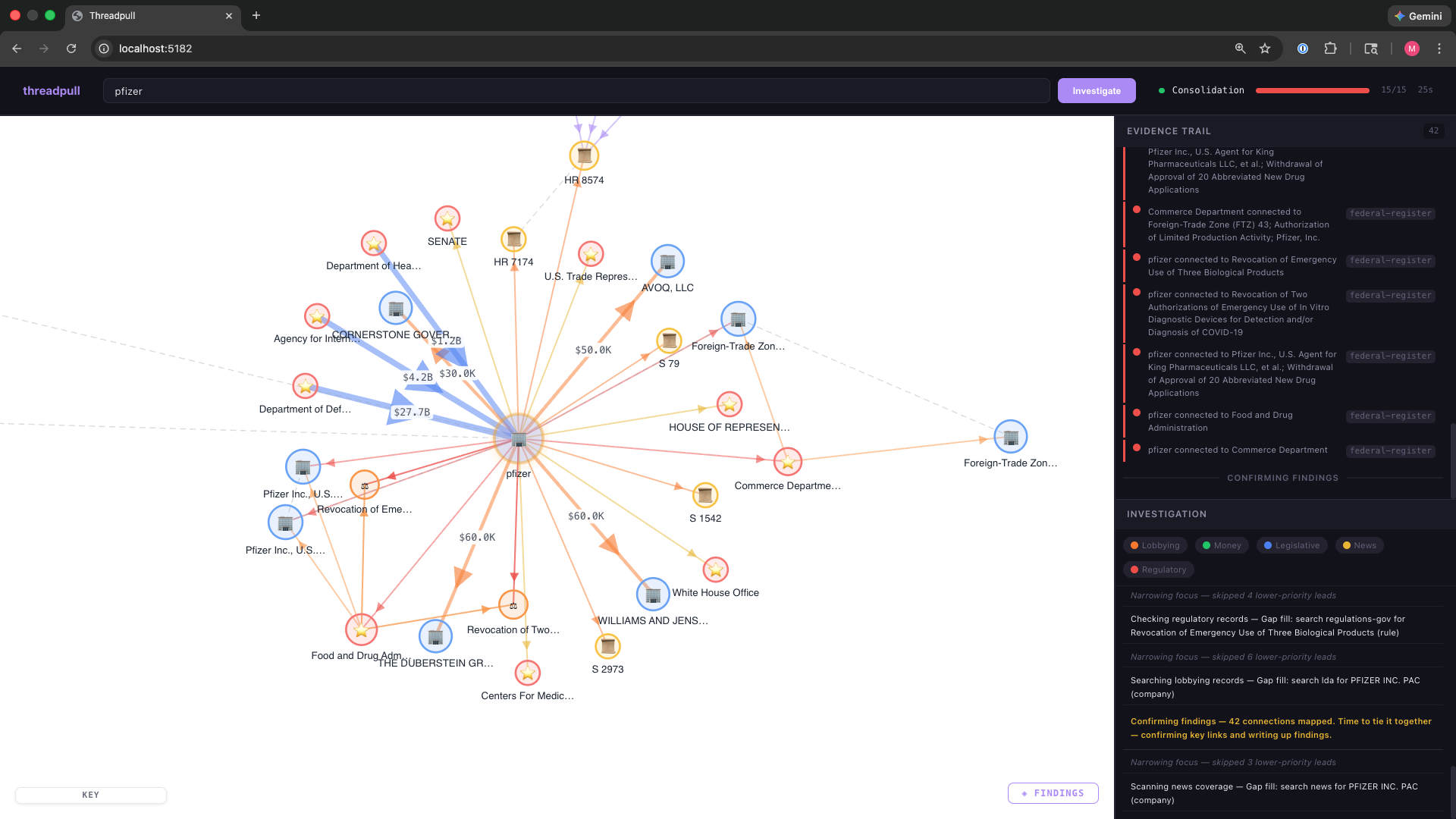
The idea is to model a newsroom: an editor agent that’s making high level decisions and multiple journalist agents chasing leads. The journalists (Legislative, Money, News, Lobbying) only query data sources and have no say in the direction of the investigation.
The editor is responsible for scoring leads to determine what to pursue next, routing to the corresponding agent, and managing budget/phase transitions.
Why it’s not live
It’s not financially feasible to put this online. Even with rate limiting, it’s too expensive to run. I’m sure I could cut costs but I feel satisfied with where it is. If you’re interested, you can email me with your questions and use case.
Why I built it
I built it mainly for educational purposes; it’s not meant for production use. My goals were:
- Get experience with LangGraph
- Break out of the RAG chatbot and typical tutorials
- Refine my workflow with Claude Code
Notice there’s nothing about the problem domain. I needed multiple, reliable and free data sources and it turns out politics meets that criteria. The same overall structure could be used to map influence in sports, fashion, etc. given access to data sources.
Approach
I acted more like a founder than a CTO. I did give technical guidelines but my focus was on the product. I was less concerned with the implementation and more concerned with the outcome.
Workflow
What went well
I’ve come up with my own blue team vs red team protocol when starting a new project. After brainstorming and choosing an idea, I then refine the project by alternating between models (and purposefully withholding the context that led to the idea). I flip-flopped between Claude (Opus 4.6) and ChatGPT 5.2 to challenge assumptions and find blindspots. My CLAUDE.md was ready to go.
What didn’t
I generated a TASKS.md file to break down the project into 7 phases. The idea is to have me act as a gatekeeper at the end of each phase. I also added instructions for us to pair on Phase 4 so I could learn about LangGraph.
In practice, I didn’t add much as a gatekeeper. The project was well enough structured that Claude did not go off the rails. It’s also my first serious agent project, so I’m not opinionated on structure or implementation details.
Pairing during the LangGraph implementation didn’t work either. For example, task 4.2 (Define the StateGraph) required me to build a type object with reducer functions to merge state. It didn’t feel like I was learning. Most of it was finding the right Zod methods and asking Claude what was expected of the reducers. In a turn of events, it was I who was writing the boilerplate.
How to learn
By the time the project reached a demo-able state, I didn’t have a good understanding of the system. I’d iterated over the original plan countless times and added significant complexity.
More than attempting at writing the LangGraph boilerplate myself, going back and asking Claude for a codebase tour was the most productive. Make sure you ask for code snippets, tradeoffs, and architecture. The ability to ask thousands of follow-up questions is amazing.
Challenge the decisions you or Claude made and you’ll have plenty to think about.
Iterating
Things inevitably go wrong and iterating was frustrating.
On different occasions, I’ve reached what I’m calling the “knob turning” issue. “Knob turning” happens when a system has a bunch of configs—weights, classification, penalties, bonuses, etc.—that become the center of attention for the LLM. Claude gets tunnel vision trying to find the right combination.
For example, the editor node is responsible for choosing what lead to pursue next. A graph that’s built on a single data source lacks the convergence factor: discovering previously unknown connections between entities. Here’s one way to promote diversity:
function computeDiversityPenalty(consecutiveCount: number, phase: InvestigationPhase): number {
if (phase === 'exploration') {
if (consecutiveCount === 0) return 0;
if (consecutiveCount === 1) return 0.15;
if (consecutiveCount === 2) return 0.25;
return 0.35;
}
if (consecutiveCount < 2) return 0;
return Math.min(0.20, 0.05 + consecutiveCount * 0.05);
}I assume that by turning these knobs back and forth, it’s attempting to reach the sweet spot, but the perfect config will rarely fix the bug.
I had a set of queries that I used as benchmarks to measure the effectiveness of my system. For example, I know there’s a lot of data on Nancy Pelosi. A sparse graph after that investigation means something is broken.
For 10+ iterations, Claude kept turning knobs with only marginal improvement. It wasn’t until I suggested the issue might be upstream that Claude was able to fix the bug. The config was fine: we just needed more data sources to build a rich graph.
Takeaway: when the model keeps tweaking config, ask whether the fix is upstream—data, graph shape—instead of in the knobs.
Conclusion
As an engineer, the reality of these AI-first projects is that they feel a bit loose. There’s no way I could reproduce all that D3 code without some serious studying. If Claude was down, I might struggle to add a significant feature, but that’s okay. The paradigm shift is accepting that you don’t need to own every line as long as you can direct, debug, and learn from the system after. I’m okay with that.
Written by Martin Camacho
← Back to blog